
- Published on
Demystifying Site Reliability Engineering (SRE) Principles, Practices, and Impact
- Authors

- Name
- Adil ABBADI
Introduction
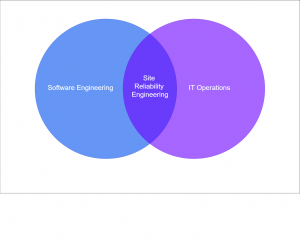
Site Reliability Engineering (SRE) bridges the gap between software engineering and IT operations, introducing a culture of reliability, automation, and measurable performance. As businesses increasingly depend on large-scale, distributed systems, SRE emerges as a critical discipline to ensure services remain fast, reliable, and always available.

- The Core Principles of SRE
- Practical SRE: Incident Management and Automation
- SRE Tools and Best Practices
- Conclusion
- Explore SRE Further
The Core Principles of SRE
Understanding the foundational principles of SRE is key to effectively applying its practices in modern infrastructure.
- Embracing Risk: SRE recognizes that absolute reliability is often unattainable and sometimes unnecessary. By quantifying acceptable risk with Service Level Objectives (SLOs), organizations can balance innovation and stability.
- Reducing Toil: Manual, repetitive operational work is minimized through automation, freeing engineers for high-impact problem-solving.
- Measuring Everything: Continuous monitoring and data-driven decision-making underpin SRE’s approach to reliability.
# Example of defining an SLO in Python-like pseudocode
service_level_objective = {
"availability": "99.9%",
"latency": "≤ 400ms for 99% of requests",
"error_rate": "≤ 0.1%"
}
SRE encourages measurement over intuition, fostering transparency and accountability.

Practical SRE: Incident Management and Automation
SRE isn’t just about setting metrics—it’s about how teams respond to incidents and automate recovery.
Incident Management When incidents strike, swift and systematic response is crucial. SRE teams utilize runbooks, blameless postmortems, and structured on-call rotations to minimize downtime and foster learning.
# Pseudocode for an alerting rule in Prometheus
alert: HighLatency
expr: http_request_duration_seconds_bucket{le="0.5"} > 0.05
for: 5m
labels:
severity: "critical"
annotations:
summary: "High latency detected on endpoint"
Automation Everywhere Automation is woven into the fabric of SRE:
- Automated deployments
- Self-healing scripts
- Infrastructure as code
This not only reduces toil but also ensures consistency and speed.
SRE Tools and Best Practices
SREs leverage a suite of modern tools and best practices to achieve their goals.
Monitoring & Observability Popular tools include Prometheus, Grafana, and Datadog, providing real-time insights and alerting.
# Example SRE workflow for continuous health checks
def health_check(service):
try:
response = service.ping()
assert response.status == 200
log("Service healthy")
except Exception:
alert_ops_team("Service unhealthy")
Error Budgets and Release Engineering Error budgets align development velocity with system reliability; if the error rate exceeds budget, feature releases pause for remediation.
Blameless Culture Root-cause analysis is performed without assigning blame, encouraging openness and rapid learning.
Conclusion
Site Reliability Engineering has profoundly shaped how modern organizations approach system reliability, scalability, and operational efficiency. By consistently applying SRE principles and leveraging automation and solid metrics, teams deliver resilient services at scale—while maintaining a culture of learning and continuous improvement.
Explore SRE Further
Ready to make your systems more reliable? Start by reviewing your SLOs, automating your incident response, and fostering a blameless culture. The journey to reliability begins with a single, measurable step!