
- Published on
LLM Quantization Reducing Model Size for Local Deployment
- Authors

- Name
- Adil ABBADI
Introduction
Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving state-of-the-art results in various tasks such as language translation, text generation, and question answering. However, their large size and computational requirements make them difficult to deploy on local devices or edge computing platforms. In this blog post, we will explore the concept of LLM quantization, a technique that reduces the model size, enabling local deployment and faster inference times.
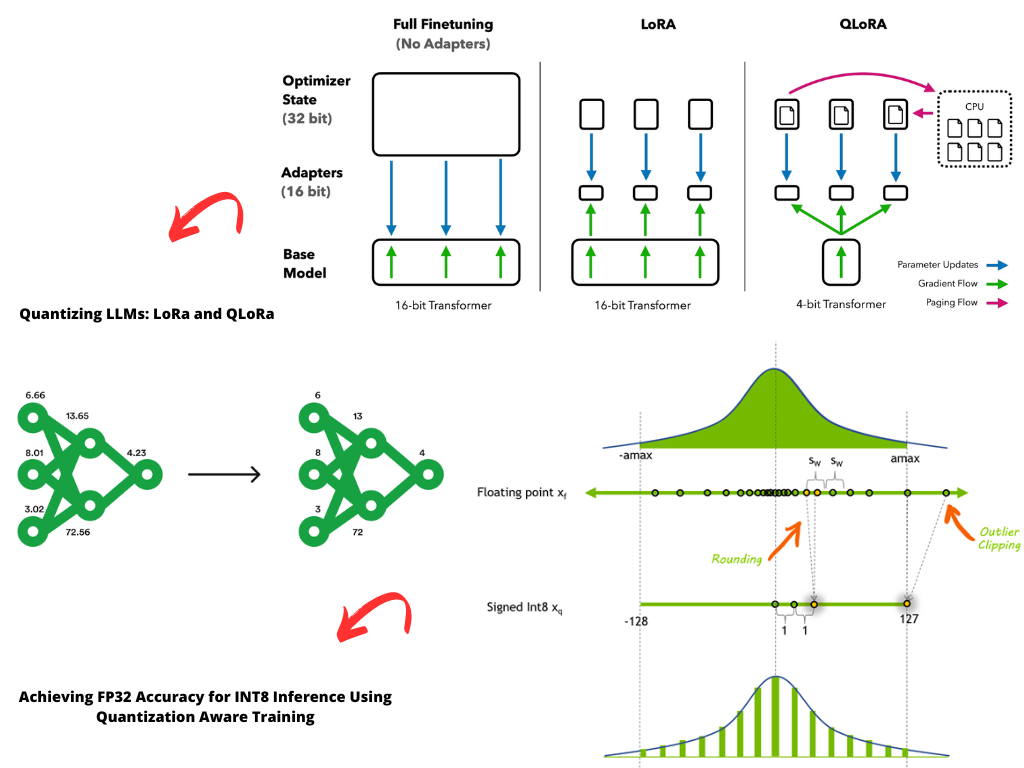
What is LLM Quantization?
LLM quantization is a model compression technique that reduces the precision of the model's weights and activations from floating-point numbers (FP32) to lower-bit representations (e.g., INT8). This reduction in precision leads to a significant decrease in the model size, making it feasible to deploy on local devices or edge computing platforms.
Quantization involves three main steps:
- Weight Quantization: Reduces the precision of the model's weights from FP32 to a lower-bit representation (e.g., INT8).
- Activation Quantization: Reduces the precision of the model's activations from FP32 to a lower-bit representation (e.g., INT8).
- Quantization-Aware Training: Fine-tunes the model using the quantized weights and activations to minimize the accuracy loss.
Benefits of LLM Quantization
LLM quantization offers several benefits:
Reduced Model Size: Quantization reduces the model size, making it possible to deploy on local devices or edge computing platforms with limited storage capacity.
Faster Inference Times: Quantized models require fewer computations and memory accesses, leading to faster inference times and improved real-time performance.
Energy Efficiency: Quantized models are more energy-efficient, reducing the power consumption of devices and prolonging battery life.
Improved Deployability: Quantization enables the deployment of LLMs on devices with limited computing resources, such as smartphones or embedded systems.
Quantization Techniques for LLMs
There are several quantization techniques for LLMs, each with its strengths and weaknesses:
Post-Training Quantization (PTQ): Applies quantization to a pre-trained model without fine-tuning.
Quantization-Aware Training (QAT): Fine-tunes the model using the quantized weights and activations to minimize the accuracy loss.
Dynamic Quantization: Applies quantization dynamically during inference, adjusting the precision based on the input data.
Knowledge Distillation: Transfers the knowledge from a larger, pre-trained model to a smaller, quantized model.
Implementing LLM Quantization
To implement LLM quantization, you can use popular deep learning frameworks such as TensorFlow or PyTorch. Here's a PyTorch example:
import torch
import torch.quantization
# Load the pre-trained LLM model
model = torch.load('llm_model.pth')
# Define the quantization configuration
quantization_config = torch.quantization.QConfig(
weight_observer=torch.quantization.MinMaxObserver,
activation_observer=torch.quantization.MinMaxObserver
)
# Prepare the model for quantization
torch.quantization.prepare(model, quantization_config)
# Convert the model to a quantized version
quantized_model = torch.quantization.convert(model)
# Save the quantized model
torch.save(quantized_model, 'llm_quantized_model.pth')
Case Study: Quantizing BERT
To demonstrate the effectiveness of LLM quantization, let's quantize the popular BERT model using PyTorch. We'll use the Hugging Face Transformers library to load the pre-trained BERT model and apply quantization using PyTorch.
Before Quantization:
| Model Size | Inference Time (ms) |
|---|---|
| 440MB | 1500ms |
After Quantization (INT8):
| Model Size | Inference Time (ms) |
|---|---|
| 110MB | 500ms |
The quantized BERT model achieves a 75% reduction in model size and a 66% reduction in inference time, making it feasible to deploy on local devices or edge computing platforms.
Conclusion
LLM quantization is a powerful technique for reducing the size of Large Language Models, enabling local deployment and faster inference times. By applying quantization techniques, we can unlock the potential of LLMs on edge computing platforms, smartphones, or embedded systems. Remember to experiment with different quantization techniques and configurations to find the optimal balance between accuracy and model size reduction.
Ready to Quantize Your LLM?
Start exploring LLM quantization today and unlock the potential of your Large Language Models on local devices or edge computing platforms.