
- Published on
Unveiling the Powerhouse A Deep Dive into BERT Architecture
- Authors

- Name
- Adil ABBADI
BERT, or Bidirectional Encoder Representations from Transformers, has been the darling of the Natural Language Processing (NLP) community since its inception in 2018. The brainchild of Google researchers, BERT has proven to be a game-changer for NLP tasks, question answering, and text classification. But have you ever wondered what makes it tick?
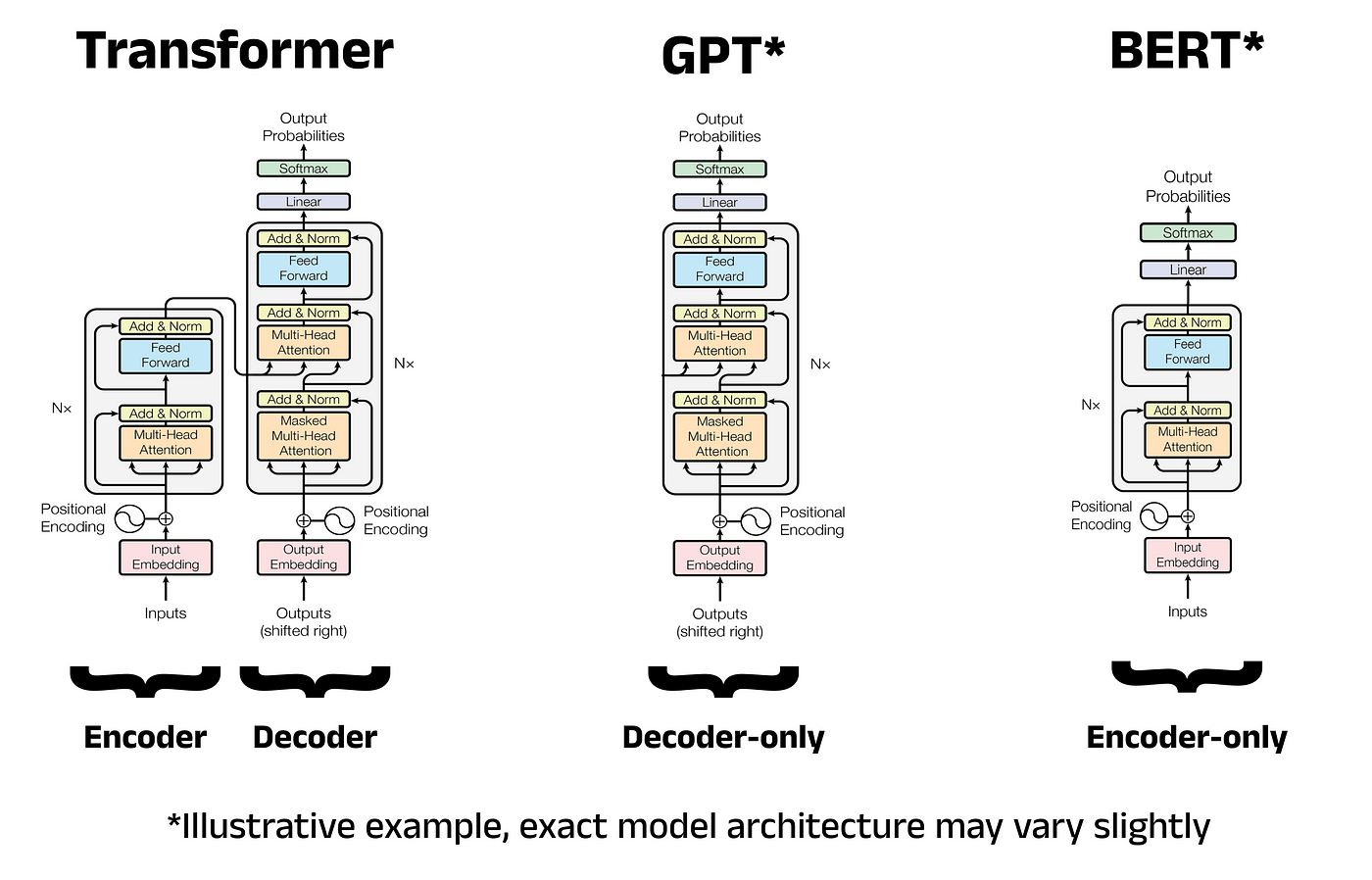
- Understanding the Transformer Architecture
- BERT Architecture: Encoder and Embeddings
- Pooler and Fine-Tuning
- Conclusion
- Take Your NLP Skills to the Next Level
Understanding the Transformer Architecture
Before diving into BERT's architecture, it's essential to understand the foundation it's built upon – the Transformer. Introduced in the paper "Attention is All You Need" by Vaswani et al. in 2017, the Transformer revolutionized the field of machine translation by replacing traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) with self-attention mechanisms.
import torch
import torch.nn as nn
class TransformerModel(nn.Module):
def __init__(self, num_heads, hidden_size, output_size):
super(TransformerModel, self).__init__()
self.encoder = nn.TransformerEncoderLayer(d_model=hidden_size, nhead=num_heads)
self.decoder = nn.TransformerDecoderLayer(d_model=hidden_size, nhead=num_heads)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, src, tgt):
output = self.encoder(src)
output = self.decoder(output, tgt)
output = self.fc(output)
return output
BERT Architecture: Encoder and Embeddings
BERT's architecture is primarily composed of two components: the Encoder and the Pooler. The Encoder is responsible for generating contextualized representations of the input sequence. It's constructed by stacking multiple identical layers, each consisting of a multi-head self-attention mechanism, and a feed-forward network (FFNN).
import torch.nn as nn
class BertEncoder(nn.Module):
def __init__(self, layer, num_layers):
super(BertEncoder, self).__init__()
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(num_layers)])
def forward(self, hidden_states, attention_mask):
for layer in self.layer:
hidden_states = layer(hidden_states, attention_mask)
return hidden_states
The input embeddings in BERT are a combination of three embeddings:
- Token Embeddings: Each token in the input sequence is represented by a unique vector.
- Segment Embeddings: These embeddings capture the context of the input, such as whether two segments belong to the same sentence or not.
import torch.nn as nn
class BertEmbeddings(nn.Module):
def __init__(self, vocab_size, hidden_size, max_position_embeddings, type_vocab_size):
super(BertEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
self.position_embeddings = nn.Embedding(max_position_embeddings, hidden_size)
self.token_type_embeddings = nn.Embedding(type_vocab_size, hidden_size)
def forward(self, input_ids, token_type_ids):
input_embeddings = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = input_embeddings + position_embeddings + token_type_embeddings
return embeddings
Pooler and Fine-Tuning
The Pooler is responsible for generating a fixed-size representation of the input sequence, which is then used for downstream NLP tasks. During fine-tuning, the Pooler is modified to accommodate the specific task, such as sentiment analysis or question answering.
import torch.nn as nn
class BertPooler(nn.Module):
def __init__(self, hidden_size):
super(BertPooler, self).__init__()
self.dense = nn.Linear(hidden_size, hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token (CLS token) as the representation.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
Conclusion
BERT has undoubtedly revolutionized the NLP landscape, achieving state-of-the-art results in numerous tasks. By understanding the architecture and component of this powerhouse, you'll be better equipped to tackle complex NLP challenges and harness the full potential of BERT in your projects.
Take Your NLP Skills to the Next Level
Ready to dive deeper into the world of NLP applications, from text classification to language translation? Explore our comprehensive guide to NLP with Python and unlock the full potential of your NLP skills.