
- Published on
Best Practices for Effective Machine Learning Ops (MLOps)
- Authors

- Name
- Adil ABBADI
Introduction
As machine learning applications transition from prototypes to production, the need for robust processes becomes critical. This is where Machine Learning Operations (MLOps) comes in—bridging the gap between model development and deployment, ensuring continuous delivery, reproducibility, and scalable ML pipelines. In this guide, we’ll explore foundational MLOps practices, complete with actionable code snippets and illustrative examples.
- Version Control for Data and Models
- Automated CI/CD for ML Pipelines
- Monitoring and Model Management in Production
- Conclusion
- Ready to Elevate Your MLOps Game?
Version Control for Data and Models
Managing data and models efficiently is crucial for reproducing experiments and scaling workflows. Unlike traditional software, ML projects require versioning not just code, but also datasets and model artifacts.
Popular tools for this purpose include DVC (Data Version Control) and MLflow. Here’s an example of tracking data and model versions using DVC:
# Initialize DVC in your project
dvc init
# Track a new dataset
dvc add data/training_data.csv
# Commit the .dvc file to Git
git add data/training_data.csv.dvc .gitignore
git commit -m "Track training data with DVC"
# Push data to remote
dvc remote add -d myremote s3://mybucket/dvcstore
dvc push
Versioning ensures consistency across experiments, making it easier to roll back to previously successful configurations.
Automated CI/CD for ML Pipelines
Continuous Integration and Continuous Deployment (CI/CD) streamlines the process of validating, testing, and deploying ML models. Automated pipelines catch issues early, ensure reproducibility, and enable faster iteration cycles.
You can use tools like GitHub Actions, Jenkins, or Kubeflow Pipelines to set up CI/CD workflows. Example: Running automated tests and training jobs with GitHub Actions.
# .github/workflows/ci-mlops.yml
name: ML CI Pipeline
on: [push]
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.9'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run unit tests
run: pytest tests/
- name: Train model
run: python train.py
Automated CI/CD adds reliability by continuously testing models and ensuring only validated artifacts progress to production.
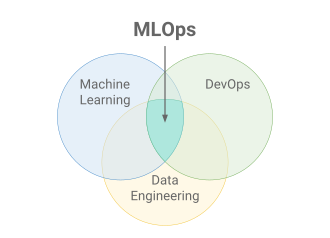
Monitoring and Model Management in Production
Once deployed, ML models require ongoing monitoring. Key aspects include tracking data drift, monitoring model performance, and rolling back underperforming models. Tools like Prometheus, Grafana, and Seldon Core facilitate robust model monitoring.
Example: Monitoring model inference latency and accuracy using Prometheus in a Python service.
from prometheus_client import start_http_server, Summary
import random
import time
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
@REQUEST_TIME.time()
def infer():
time.sleep(random.random())
if __name__ == '__main__':
start_http_server(8000)
while True:
infer()
Dashboarding solutions like Grafana can visualize these metrics, enabling teams to act proactively in response to anomalies or performance degradations.

Conclusion
MLOps streamlines the complex journey of building, deploying, and maintaining machine learning models in production environments. By adopting robust version control, automated CI/CD, and proactive monitoring, organizations can achieve reliable, reproducible, and scalable ML workflows.
Ready to Elevate Your MLOps Game?
Embrace these MLOps practices to accelerate innovation, minimize risk, and extract maximum value from your machine learning initiatives. Start implementing small improvements today, and watch your ML team thrive!