
- Published on
Mastering BERT Model Fine-tuning Techniques for Superior NLP Performance
- Authors

- Name
- Adil ABBADI
- Understanding BERT's Power
- Technique 1: Task-Specific Embeddings
- Technique 2: Adaptive Pooling
- Technique 3: Multi-Task Learning
- Conclusion
- Take Your NLP Skills to the Next Level
Understanding BERT's Power
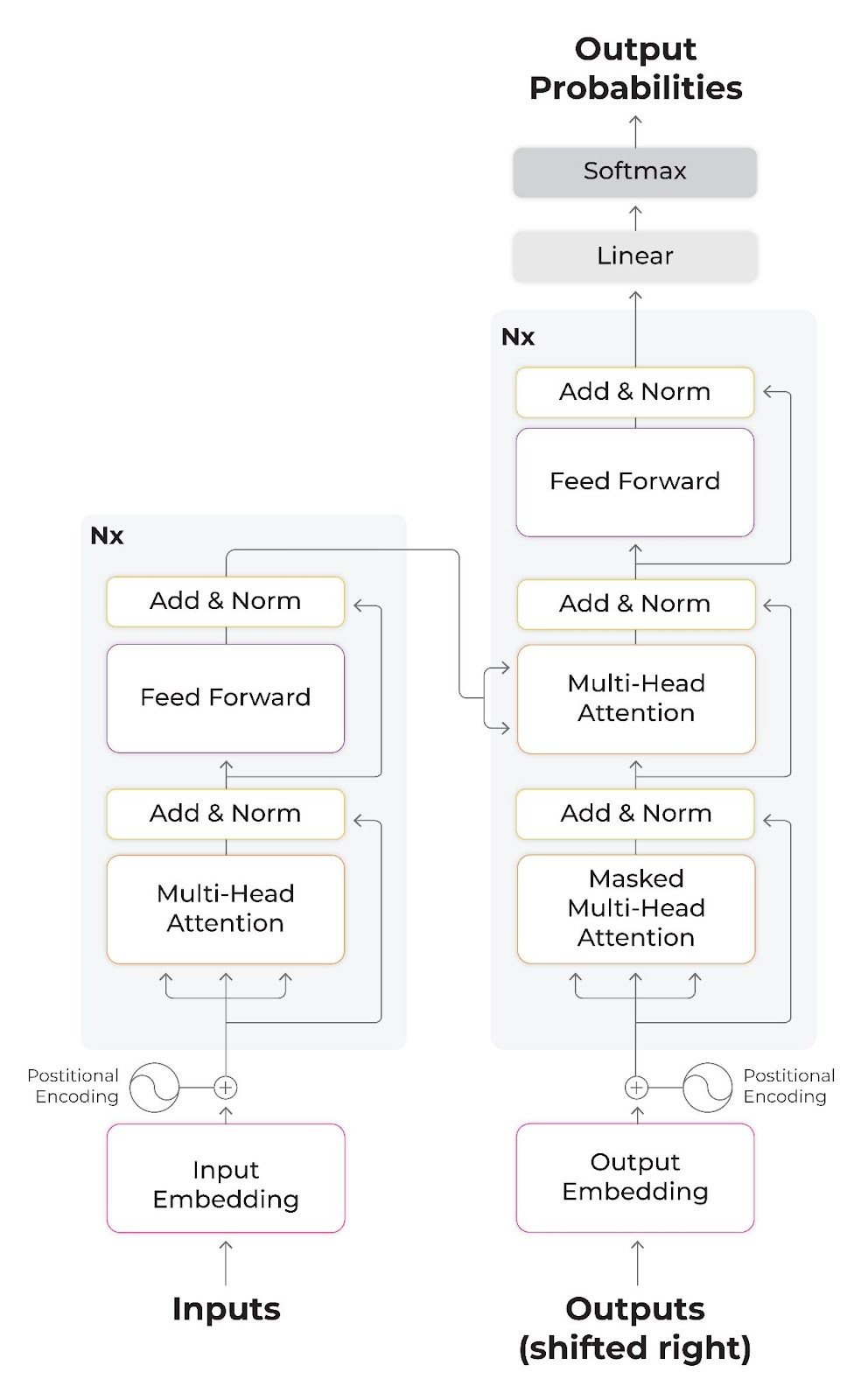
BERT (Bidirectional Encoder Representations from Transformers) has revolutionized the Natural Language Processing (NLP) landscape with its impressive performance on a wide range of benchmarks. By pre-training a deep neural network on a large corpus of text, BERT learns to capture intricate language patterns and contextual relationships. However, to fine-tune BERT for a specific NLP task, one needs to adapt the model to the task's specific requirements. In this article, we'll delve into the latest BERT fine-tuning techniques to help you achieve superior NLP results.
import torch
from transformers import BertTokenizer, BertModel
# Load pre-trained BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
Technique 1: Task-Specific Embeddings
One effective fine-tuning technique is to learn task-specific embeddings for each input sample. This involves adding a learned embedding layer on top of the pre-trained BERT model. This technique is particularly useful when dealing with datasets that contain out-of-vocabulary (OOV) tokens.
import torch.nn as nn
class TaskSpecificEmbeddings(nn.Module):
def __init__(self, hidden_size):
super(TaskSpecificEmbeddings, self).__init__()
self.embedding_layer = nn.Linear(hidden_size, hidden_size)
def forward(self, input_ids):
embeddings = self.model.get_input_embeddings()(input_ids)
embeddings = self.embedding_layer(embeddings)
return embeddings
Technique 2: Adaptive Pooling
Adaptive pooling is another powerful fine-tuning technique that involves learning a weighted sum of the hidden states of the BERT model. This technique is particularly useful when dealing with datasets that have varying lengths.
import torch.nn.functional as F
class AdaptivePooling(nn.Module):
def __init__(self, hidden_size):
super(AdaptivePooling, self).__init__()
self.pooling_layer = nn.Linear(hidden_size, hidden_size)
def forward(self, hidden_states):
weights = F.softmax(self.pooling_layer(hidden_states), dim=1)
pooled_output = torch.sum(hidden_states * weights, dim=1)
return pooled_output
Technique 3: Multi-Task Learning
Multi-task learning is a technique that involves training a single model on multiple related tasks simultaneously. This technique is particularly useful when dealing with datasets that have limited annotated data.
import torch.nn as nn
class MultiTaskModel(nn.Module):
def __init__(self, hidden_size, num_tasks):
super(MultiTaskModel, self).__init__()
self.tasks = nn.ModuleList([nn.Linear(hidden_size, hidden_size) for _ in range(num_tasks)])
def forward(self, hidden_states):
outputs = []
for task in self.tasks:
output = task(hidden_states)
outputs.append(output)
return outputs
Conclusion
In this article, we explored three powerful BERT fine-tuning techniques to unlock the full potential of BERT and achieve state-of-the-art NLP performance. By mastering these techniques, you can adapt BERT to specific NLP tasks and achieve superior results.
Take Your NLP Skills to the Next Level
Unlock the full potential of BERT and take your NLP skills to the next level. Experiment with these fine-tuning techniques and explore the latest advancements in the NLP field.