
- Published on
Using OCR with OpenAI Extract, Understand, and Generate from Images
- Authors

- Name
- Adil ABBADI
Introduction
The ability to extract text from images using Optical Character Recognition (OCR) unlocks a new dimension of interaction with visual data. When you combine OCR with OpenAI's state-of-the-art language models, you create pipelines that can read, understand, and generate responses or insights from images. In this article, we'll explore practical ways to use OCR with OpenAI, covering key technologies, implementation steps, and real-world use cases.

- Understanding OCR and OpenAI: The Basics
- Building an OCR-to-OpenAI Workflow in Python
- Advanced Use Cases: Document Search, Summarization & QA
- Conclusion
- Get Creative: Start Building Your Own AI Document Workflows
Understanding OCR and OpenAI: The Basics
OCR is the technology that allows computers to "see" text inside images and convert it into machine-readable data. There are several popular Python OCR libraries, like Tesseract (via pytesseract) or EasyOCR, which can extract text from various image formats.
When paired with OpenAI's language models, this extracted text can be summarized, categorized, translated, or even transformed into creative outputs like stories or answers to questions.
Let's look at a basic pipeline for OCR and OpenAI integration:
from PIL import Image
import pytesseract
import openai
# Step 1: Use OCR to extract raw text from an image
img_path = 'sample_invoice.png'
img = Image.open(img_path)
raw_text = pytesseract.image_to_string(img)
# Step 2: Send the extracted text to OpenAI
openai.api_key = 'YOUR_OPENAI_API_KEY'
response = openai.Completion.create(
engine='text-davinci-003',
prompt=f"Summarize the following invoice:\n\n{raw_text}",
max_tokens=100
)
print(response.choices[0].text.strip())
Building an OCR-to-OpenAI Workflow in Python
Let's dive deeper and build a fully functional workflow that takes an image, applies OCR, and then utilizes OpenAI to interpret or enhance the text. This process is especially powerful for automating tasks like invoice analysis, receipt transcription, or extracting key data from forms.
Step 1: OCR Extraction with Pytesseract
import pytesseract
from PIL import Image
def extract_text_from_image(image_path):
image = Image.open(image_path)
text = pytesseract.image_to_string(image)
return text.strip()
document_text = extract_text_from_image("sample_receipt.jpg")
print(document_text)
Step 2: Leveraging OpenAI for Intelligent Analysis
Once text is extracted, pass it to an OpenAI model for summarization, Q&A, or further processing.
import openai
openai.api_key = 'YOUR_OPENAI_API_KEY'
def analyze_text_with_openai(prompt_text):
prompt = f"Extract the items and prices from this receipt:\n\n{prompt_text}"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=150,
temperature=0.2
)
return response.choices[0].text.strip()
result = analyze_text_with_openai(document_text)
print(result)

Advanced Use Cases: Document Search, Summarization & QA
By combining OCR and OpenAI, you can automate powerful workflows:
1. Intelligent Search in Scanned Documents
Suppose you have a directory of scanned contracts and you want to search for contracts mentioning "Force Majeure":
import os
def search_documents_for_keyword(dir_path, keyword):
matches = []
for file in os.listdir(dir_path):
if file.endswith('.png') or file.endswith('.jpg'):
text = extract_text_from_image(os.path.join(dir_path, file))
if keyword.lower() in text.lower():
matches.append(file)
return matches
found_files = search_documents_for_keyword('contracts/', 'Force Majeure')
print(f"Contracts mentioning 'Force Majeure': {found_files}")
2. Automatic Summarization of Extracted Text
def summarize_text_with_openai(text):
prompt = f"Summarize this legal document in plain English:\n\n{text}"
summary = openai.Completion.create(
engine="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=100
)
return summary.choices[0].text.strip()
summary = summarize_text_with_openai(document_text)
print("Document Summary:", summary)
3. Q&A on OCR-Extracted Content
def question_answer_ocr_text(image_path, question):
context = extract_text_from_image(image_path)
prompt = f"Given the following document content:\n\n{context}\n\nAnswer: {question}"
answer = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=60
)
return answer.choices[0].text.strip()
response = question_answer_ocr_text("sample_letter.png", "What is the total payment due?")
print("Q&A Result:", response)
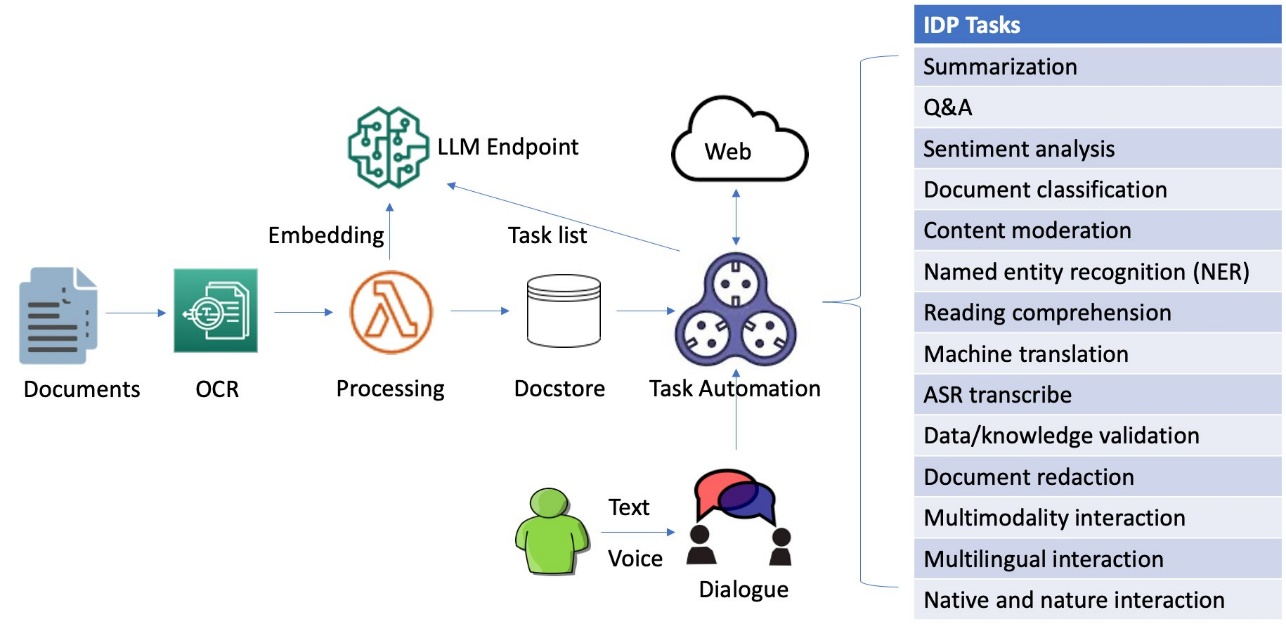
Conclusion
Combining OCR with OpenAI unleashes the capability to not just extract data from images, but to deeply understand and interact with it. From automating document workflows to building smart search tools and AI assistants, the opportunities are vast and growing as both OCR and language models evolve.
Get Creative: Start Building Your Own AI Document Workflows
Ready to level up your document processing? Experiment with these techniques on your own datasets, and see how OCR and OpenAI can help you make sense of the information hidden within images. The future of AI-powered visual understanding is here—start building today!