
- Published on
Mastering Data Engineering with Apache Spark Concepts, Techniques, and Best Practices
- Authors

- Name
- Adil ABBADI
Introduction
Apache Spark has become a cornerstone technology for data engineering, offering robust APIs and immense scalability for handling large datasets. Whether you are building data pipelines, performing transformations, or enabling real-time analytics, Spark’s in-memory computation engine stands out in the modern data landscape.

- Understanding Apache Spark in Data Engineering
- Building Scalable ETL Pipelines with Spark
- Real-Time Data Processing with Spark Streaming
- Conclusion
- Ready to Build with Spark?
Understanding Apache Spark in Data Engineering
At its core, Apache Spark is a distributed processing engine designed to handle big data workloads efficiently. It provides high-level APIs for Java, Scala, Python, and R, making it accessible across different environments.
Spark’s main abstraction, the Resilient Distributed Dataset (RDD), enables fault-tolerant and parallelized data operations.
from pyspark import SparkContext
sc = SparkContext("local", "Data Engineering Example")
rdd = sc.parallelize([1, 2, 3, 4, 5])
squared = rdd.map(lambda x: x * x)
print(squared.collect()) # Output: [1, 4, 9, 16, 25]
Spark also offers DataFrame and Dataset APIs, which provide higher-level abstractions for data manipulation and are optimized through Catalyst and Tungsten engines.

Building Scalable ETL Pipelines with Spark
Data engineers rely on Spark to build Extract, Transform, Load (ETL) pipelines that are both scalable and resilient. A typical ETL process with Spark involves reading data from various sources, transforming it, and writing it to a specified destination.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('ETL Example').getOrCreate()
# Extract: Load data from CSV
df = spark.read.csv('input/data.csv', header=True, inferSchema=True)
# Transform: Data cleaning and manipulation
cleaned_df = df.dropna().filter(df['value'] > 10)
# Load: Write to Parquet format for analytics
cleaned_df.write.parquet('output/cleaned_data.parquet')
Key considerations when designing ETL workflows with Spark include:
- Partitioning data for parallelism.
- Choosing the right file formats (e.g., Parquet, ORC).
- Leveraging Spark’s Catalyst optimizer for query optimization.

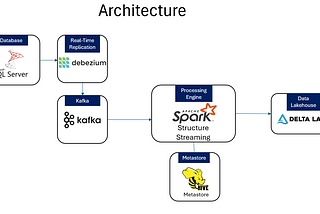
Real-Time Data Processing with Spark Streaming
Apache Spark extends its capabilities through Spark Streaming and Structured Streaming APIs, enabling data engineers to process and analyze streaming data in real time. This is particularly useful in scenarios where businesses need insights as events happen—such as monitoring logs, financial transactions, or IoT devices.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamExample").getOrCreate()
# Structured Streaming: Read data from socket stream
streaming_df = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
# Simple transformation: Word count
from pyspark.sql.functions import explode, split
words = streaming_df.select(explode(split(streaming_df.value, " ")).alias("word"))
word_counts = words.groupBy("word").count()
# Output results to console
query = word_counts.writeStream.outputMode("complete").format("console").start()
query.awaitTermination()
When working with streaming data, it is crucial to:
- Manage stateful computations.
- Ensure fault tolerance via checkpointing.
- Optimize window sizes for batching operations.
Conclusion
Apache Spark has revolutionized data engineering by providing a unified platform for batch and real-time data processing at scale. Its flexible APIs, efficient memory management, and built-in optimization make it indispensable for contemporary data pipelines and analytics applications. By mastering its core components and best practices, data engineers can unlock transformative business value from their data assets.
Ready to Build with Spark?
The best way to master Apache Spark is through hands-on experimentation. Try building your own ETL pipeline or streaming application, and explore advanced features like machine learning integration or graph processing. The Spark community is vast and active—reach out, contribute, and keep your data engineering skills ahead of the curve!